你以为在给 AI 下命令,其实你在改写它的概率分布
|
freeflydom 2026年3月3日 9:43
本文热度 3427
2026年3月3日 9:43
本文热度 3427
|
只要输入一句话,AI 就会按要求完成任务。
于是一个几乎本能的结论产生了:
👉 Prompt 就是在给 AI 下命令。
这听起来非常合理:
这些表达方式与人类日常交流中的指令形式高度一致。
但如果回到模型的真实工作机制,会发现一个非常反直觉的事实:
❗ 一个关键认知
在模型内部:
从来不存在“命令执行系统”。
Prompt:
- 不会触发任务模块
- 不会被解析为操作指令
- 不会启动“执行流程”
对模型来说,它始终只是:
一段需要继续往下接的文本。
理解这一点,是理解 Prompt Engineering 的真正起点。
一、模型眼中的 Prompt:只是“条件上下文”
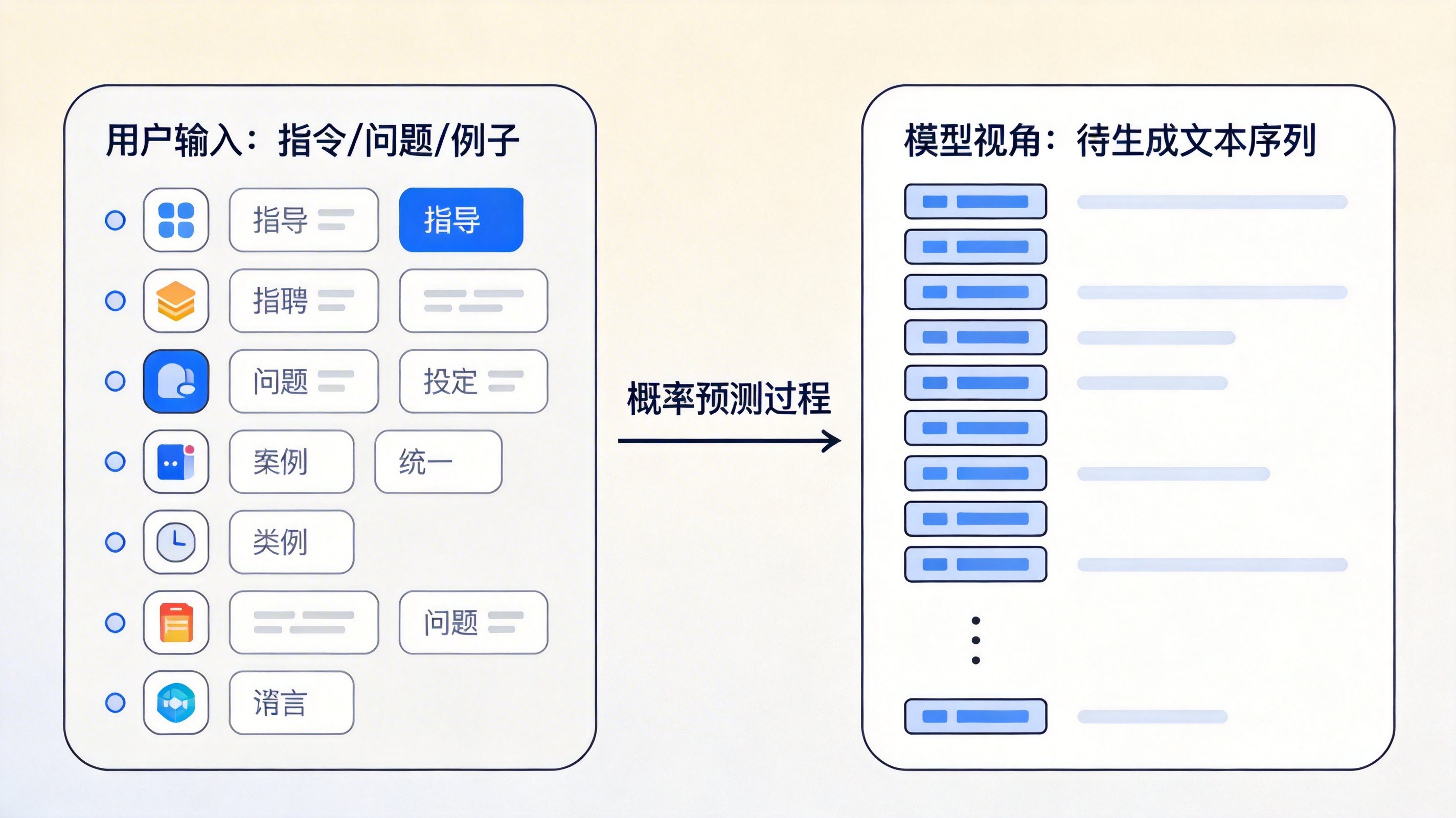
预测下一个最可能出现的 token:
P(tokenₜ | token₁…tokenₜ₋₁)
这意味着一个极其重要的结论:
模型不会区分:
在它看来,这些都是:
👉 同一种东西:输入序列的一部分。
✅ Prompt 的真实本质
Prompt 并不是在“告诉模型做什么”。
它真正做的是:
改变条件概率分布。
换句话说:
- Prompt 不在下命令
- Prompt 在改变“下一步最可能出现什么”
这才是提示词工程的底层逻辑。
二、为什么 Prompt 看起来像“指令”?

为什么输入“请帮我总结”,它真的会去总结?
答案很简单:
👉 统计规律。
在海量训练数据中,存在大量稳定模式:
- “请帮我总结:” → 后面通常是摘要
- “翻译成英文:” → 后面通常是译文
- “写一篇文章:” → 后面通常是完整文章
模型并没有理解这些句子的“命令性”。
它只是学到了一个统计事实:
当某种语言结构出现时,后续文本通常遵循某种结构。
🔎 实际发生的过程
当你输入:
“请帮我写一篇关于 AI 的文章”
模型内部发生的是:
1️⃣ 识别熟悉语境结构
2️⃣ 判断该结构对应的文本分布
3️⃣ 生成符合该分布的内容
整个过程没有任务执行。
本质只是:
高维语义空间中的概率推断。
三、Prompt Engineering 的真正含义
但从本质上讲:
Prompt Engineering 的核心只有一个目标:
控制概率空间。
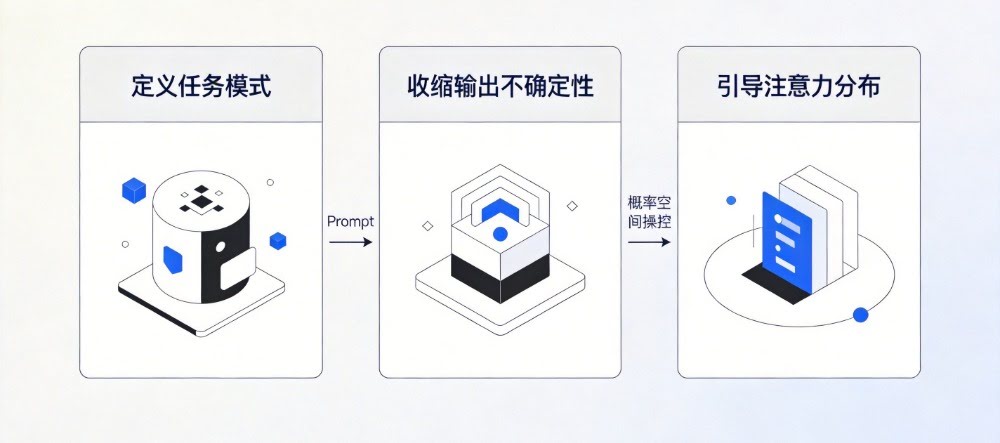
它实际上在做三件事。
1️⃣ 定义任务模式
模型并不知道自己在执行什么任务。
Prompt 的作用是让模型判断:
当前文本属于哪种语境结构:
这不是通过“理解任务”实现的,
而是通过:
👉 上下文模式识别。
2️⃣ 收缩输出不确定性
模型的预测空间极其巨大。
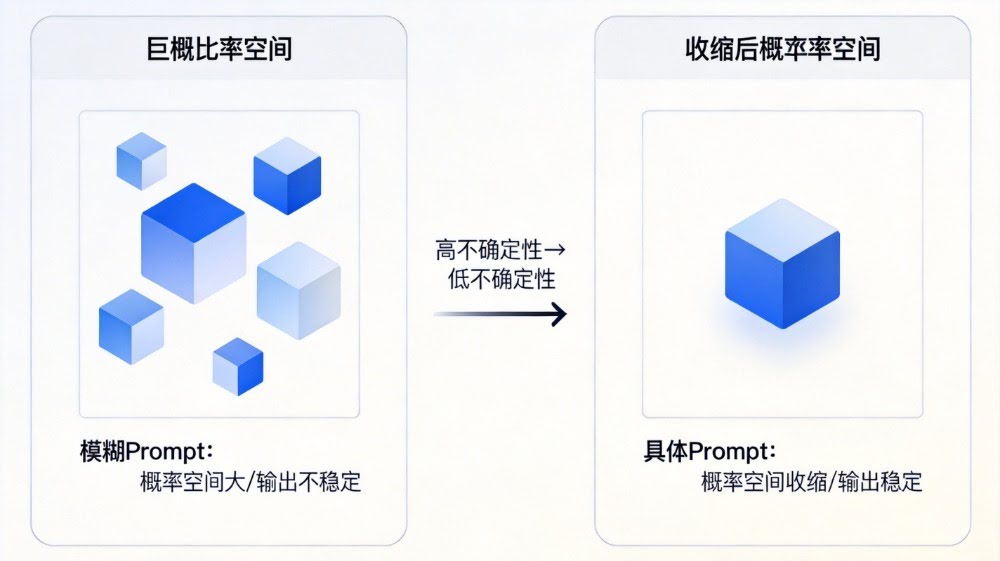
Prompt 越模糊:
可能输出路径越多。
表现为:
⭐ 核心规律
Prompt 越具体 → 输出越稳定
因为它显著减少了:
模型的预测自由度。
3️⃣ 引导注意力分布
在 Transformer 中:
每个 token 都参与注意力计算。
Prompt 结构会直接影响:
从技术角度看:
Prompt 本质是在操控注意力权重分布。
四、Few-shot 的真实原理
很多人认为:
给几个例子,模型就“学会了”。
实际上:
在推理阶段:
但它确实发生了一种特殊现象:
👉 上下文内学习(In-Context Learning)
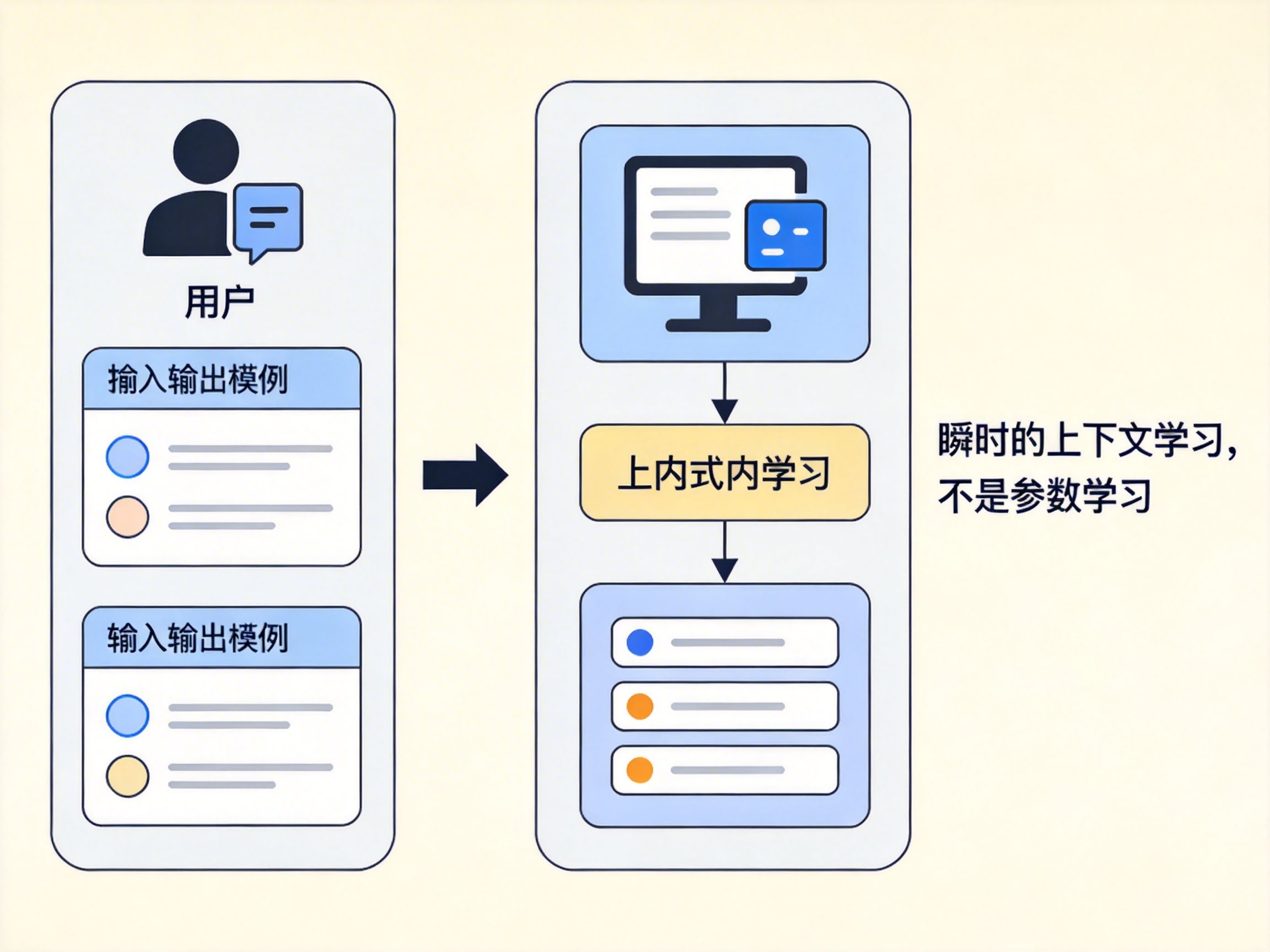
✅ Few-shot 的真实作用
Few-shot 提供的是上下文中的示例模式。
模型通过观察:
输入 → 输出
输入 → 输出
会在内部推断:
当前任务的映射规律(输入与输出之间的模式)
然后在生成阶段:
- 根据这个规律预测后续输出
- 保持与示例一致的结构和风格
🎯 关键结论
Few-shot 不是参数学习。
而是:
瞬时的上下文学习。
五、为什么 Prompt 有时会 “失效”?
原因其实很简单:
👉 概率空间仍然过大。
如果约束不足:
模型可能进入不同生成路径。
于是表现为:
🎯 Prompt 的真正任务
从来不是表达需求。
而是:
减少不确定性。
六、Prompt 的能力边界

Prompt 能改变:
但无法改变:
核心结论
Prompt 可以改变 “模型如何回答”,但不能改变 “模型知道什么”。
七、最终总结一句话
可以用最精准的一句话概括:
Prompt 不是指令系统,而是概率空间的调控工具。
它并没有让模型真正 “理解任务”。
只是让模型更容易预测:
👉 “接下来最像正确答案的文本是什么。”
转自https://www.cnblogs.com/mchao/p/19639771
该文章在 2026/3/3 9:43:03 编辑过






 400 186 1886
400 186 1886

