一、模型
模型的下载调用比数据集简单。
首先在命令行准备好以下几个工具:
pip install huggingface-cli # 这个好像不用下载,貌似huggingface-hub自带了(不太确定)
pip install hf_transfer
然后命令行开启镜像网站并加速:
export HF_ENDPOINT=https://hf-mirror.com # 镜像网站
export HF_HUB_ENABLE_HF_TRANSFER=1 # 开启加速
下载模型:
huggingface-cli download --resume-download AAA/BBB
AAA/BBB是HugglingFace官网复制的模型的名字
比如说hfl/rbt3或者distilbert/distilbert-base-uncased-finetuned-sst-2-english之类的。
也可以使用--local-dir指定下载路径。
然后调用模型就是按照官网教的方式:
# 使用Auto方法
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("hfl/rbt3")
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
# 使用pipeline方法
from transformers import pipeline
pipe = pipeline("text-classification", model="distilbert/distilbert-base-uncased-finetuned-sst-2-english")
二、数据集
数据集下载跟模型一摸一样,关键在于镜像的下载方式一般无法调用。
如果你可以科学上网,建议直接使用常用的(帮你一键下载调用):
from datasets import *
datasets = load_dataset("AAA/BBB")
不可以科学上网可以如下操作。
首先还是huggingface-cli下载数据集:
export HF_ENDPOINT=https://hf-mirror.com # 镜像网站
export HF_HUB_ENABLE_HF_TRANSFER=1 # 开启加速
huggingface-cli download --repo-type dataset --resume-download madao33/new-title-chinese
如果需要指定数据集下载路径需要使用--cache-dir(注意,跟模型下载指定路径不一样的参数)。
我们以madao33/new-title-chinese这个数据集为例(https://huggingface.co/datasets/madao33/new-title-chinese/tree/main)
在hugglingface官网是这样呈现的数据:
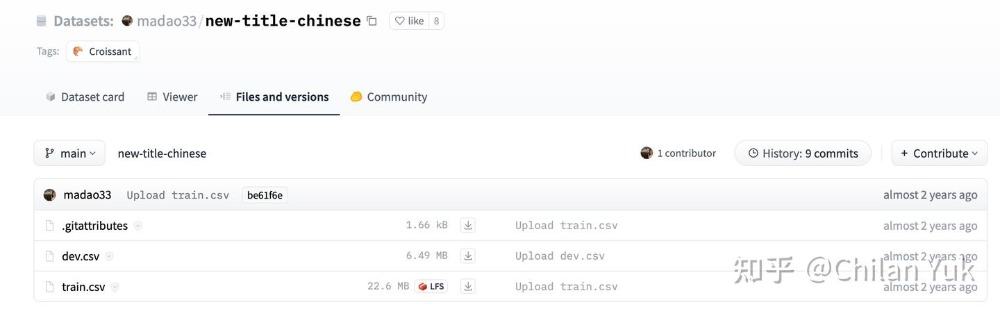
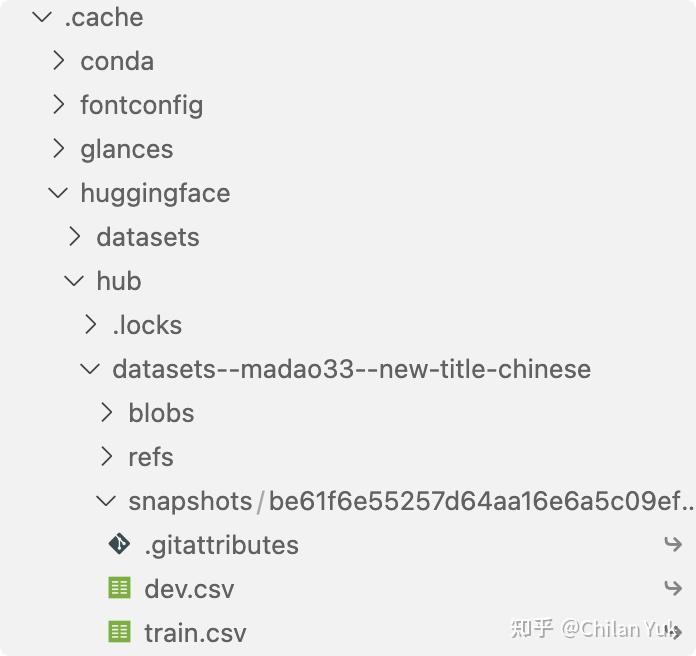
这样数据会默认帮你下载到/home/user_name/.cache/huggingface/hub/ 下,并且文件组织形式如下:
这个时候如果直接使用常规调用数据集方式如下是不成功的(因为源码还是从外网路径搜索下载网络报错
就算指定本地路径也还是报错说这个路径下没有可读取的数据):
datasets = load_dataset("madao33/new-title-chinese")
仔细探究了这个报错的各种可能性,最后发现load_dataset方法其实是自动下载外网的数据集
然后自动进行数据处理(把csv处理成了arrow格式),最后再调用给用户:

同时数据组织的路径也跟使用镜像网站不同:

那么当想直接使用本地下载的csv文件,可以这样操作:
data_files = {"train":"train.csv", "test":"dev.csv"}
datasets = load_dataset("csv", data_dir="/home/user_name/.cache/huggingface/hub/datasets--madao33--new-title-chinese/snapshots/be61f6e55257d64aa16e6a5c09ef9451e3f24c40", data_files=data_files)
data_dir填写的是你放csv数据的那个文件夹。
这样就成功了:

再举例一个非csv格式的本地数据调用:
把Dahoas/rm-static数据集下载到本地,文件夹结构如下:
-data
|-test-00000-of-00001-bf4c733542e35fcb.parquet
|-train-00000-of-00001-2a1df75c6bce91ab.parquet
-.gitattributes
-README.md
-dataset_infos.json
那么代码就可以这样写文件映射关系:
data_files = {"train":"train-00000-of-00001-2a1df75c6bce91ab.parquet","test":"test-00000-of-00001-8c7c51afc6d45980.parquet"}
raw_datasets = load_dataset("parquet", data_dir="/Your/Path/Dahoas/rm-static/data", data_files=data_files)
参考文章:原文链接
该文章在 2025/8/27 17:42:47 编辑过






 400 186 1886
400 186 1886


